스위프트 표준 라이브러리의 활용
스위프트의 표준 라이브러리는 데이터 타입, 컬렉션 타입, 함수와 메서드 그리고 다양한 목적에 부합하는 다수의 프로토콜 등, 어플리케이션을 개발하기 위한 각종 구현 요소를 제공한다.
2장에서 다루는 주요 내용은 다음과 같다.
- 스위프트의 표준 라이브러리
- 서브스크립트 구현 방식
- 수정불가immutability 데이터 타입의 이해
- 스위프트와 오브젝티브C의 상호관련성
- 스위프트의 프로토콜 지향 프로그래밍
스위프트 표준 라이브러리는 스위프트 프로그래밍 언어와 구분되는 별개의 요소이자, 클래스, 구조체, 열거형, 함수, 프로토콜 등 스위프트 언어를 활용하기 위한 핵심 도구다.
스위프트 표준 라이브러리에 포함된 함수와 메서드의 성능은 매우 우수하지만, 탁월한 성능을 유지하기 위해서는
함수 또는 메서드에 사용되는 프로토콜의 성능 또한 우수해야 한다. 예를 들어, Array.append() 함수를 살펴보자.
이 함수는 해당 배열의 저장 내용을 다른 배열과 실시간으로 공유하지 않을 경우 알고리즘의 복잡성이 O(1)만큼 커진다.
함수 실행을 위해 해당 배열을 브릿징한 NSArray 로 래핑해야 하며, 그렇지 않을 경우
알고리즘의 효율성은 매우 낮아지게 된다.
애플이 구조체를 사용하는 이유
여타 객체지향형 언어를 이용해서 프로그맹 인어를 해왔다면, 원하는 타입을 만들기 위해 클래스class라는 구조 또는 개념을 사용해 왔을 것이다. 하지만 스위프트 표준 라이브러리에서는 이와 같은 용도로 클래스를 사용하지 않으며, 스위프트에 정의된 타입 대부분은 구조체structure다.
스위프트는 왜 값 타입인 구조체를 사용해 참조 타입인 클래스를 지원하도록 한 것일까? 상속, 이니셜라이져, 레퍼런스 카운팅 등 다양한 기능을 제공하는 클래스에 비해 구조체가 표준 라이브러리의 구성 요소로서 적합하기 때문이다. 또한 구조체는 값 타입으로서, 단 하나의 소유 객체만을 지니며, 새로운 변수에 할당하거나 함수에 전달할 때는 항상 복사해서 사용한다는 점도 중요한 이유다.
구조체를 사용해 값을 전달할 때 항상 복사가 이루어지는 것처럼 보인다. 하지만 스위프트는 꼭 필요한 경우에만 복사를 만들어 사용하며, 알고리즘이 최적의 성능을 낼 수 있도록 복사한 모든 값을 관리하므로 이와 같은 자체적인 최적 할당 작업을 막아서는 안된다.
스위프트의 구조체는 여타 C 언어 기반의 구조체에 비해 훨씬 강력하며, C 기반 언어의 클래스에 가깝다.
스위프트 구조체의 주요 기능은 다음과 같다.
- 자동으로 생성되는 멤버 초기화 함수memberwise initializer 및 커스텀 초기화 함수 사용가능
- 메서드를 가질 수 있음
- 프로토콜을 구현할 수 있음
스위프트는 구조체에 강력한 기능을 제공하고 있다. 그렇다면 클래스는 언제 사용해야할까? 애플은 구조체와 클래스의 역할 분담에 대해 알 수 있도록 다음과 같은 구조체 생성 가이드라인을 제공한다.[1]
- 특정 타입 생성의 가장 중요한 목적이 간단한 몇 개의 값을 캡슐화하려는 것인 경우
- 캡슐화한 값을 구조체의 인스턴스에 전달하거나 할당할 때 참조가 아닌 복사 할 경우
- 구조체에 의해 저장되는 프로퍼티가 참조가 아닌 복사를 위한 값 타입인 경우
- 기존의 타입에서 가져온 프로퍼티나 각종 기능을 상속할 필요가 없는 경우
위와 같은 경우 구조체를 생성하고, 그렇지 않다면 참조 방식으로 인스턴스를 호출하는 클래스를 생성해서 사용한다.
스위프트에서 배열 선언
배열은 순위 목록에 동일 타입의 값을 저장하는 데이터 타입이다. 스위프트이 배열은 오브젝티브C의 배열과 몇 가지 중요한 차이점이 있는데, 그 중 첫 번째 차이점은 반드시 동일 타입의 값만 저장해야 한다는 것이다. 이는 반환될 값의 타입을 명확히 예측할 수 있게 만들며, 좀 더 효율적인 코드, 실수의 여지가 줄어든 코드를 작성하는 데 도움이 된다.
또 다른 차이점은 컬렉션 타입이 있다는 것이다. 스위프트에서 배열은 제네릭 타입의 컬렉션generic type collections이며, 어떤 타입이든 될 수 있으며, 정수, 실수, 문자열, 열겨헝은 물론 다른 컬렉션까지 포함할 수 있다.
마지막으로 스위프트 배열은 클래스가 아닌 구조체로 정의된다.
스위프트에는 다음과 같은 세 가지 유형의 배열이 있다.
- Array
- ContiguousArray
- ArraySlice
모든 Array 컬렉션은 배열에 포함된 배열 요소를 저장하기 위해 메모리 공간을 유지한다.
배열 요소의 타입이 클래스 또는 @objc 프로토콜 타입이 아닌 경우,
배열의 메모리 영역은 인접 블록에 저장된다. 반면 배열 요소의 타입이 클래스 또는 @objc 프로토콜 타입인 경우,
배열의 메모리 영역은 인접 블록에 NSArray 의 인스턴스 또는 NSArray 의 서브클래스의 인스턴스로 저장된다.
저장하려는 배열 요소가 클래스 또는 @objc 프로토콜인 경우, ContiguousArray 를 사용하면
좀 더 효율적인 코드를 작성할 수 있다. ContiguousArray 타입은 Array 구현에 사용되는
다양한 프로토콜을 공유할 수 있으며, 거의 비슷한 프로퍼티를 활용할 수 있다.
다른 점은 오브젝티브C와의 브릿징을 지원하지 않는다는 것이다.
ArraySlice 컬렉션 역시 Array, ContiguousArray 혹은 다른 ArraySlice의 속성을 그대로 지니며
마찬가지로 배열 요소를 저장할 때 인접 메모리 공간을 사용하며, 오브젝티브C와의 브릿징을 지원하지 않는다.
가장 큰 특징은 이미 존재하는 또 다른 배열 타입의 일부 그루븡ㄹ 대표한다는 것이다.
이 때문에 원본인 배열의 생애주기가 끝나면 ArraySlice 에 저장된 배열 요소 역시
접근 불가능 상태가 된다는 점을 주의해야 한다. 이런 특징을 이해하지 못할 경우 메모리 누수 또는 객체 누수가 일어날 수 있으며,
애플은 ArraySlice 인스턴스를 장시간 유지하지 말도록 권장하고 있다.
Array, ContiguousArray, ArraySlice의 인스턴스를 생성하면 해당 배열 요소를 저장하기 위한 추가 저장공간이 할당된다.
이와 같은 추가 저장 공간을 배열 용량array's capacity이라 칭하며, 이는 배열에 메모리 공간을 재할당하지 않고
배열 관련 작업을 처리할 수 있을 정도의 잠재적인 저장 공간이라 할 수 있다.
스위프트 배열은 기하급수적 증가 전략exponential growh strategy를 따르며[2],
배열에 요소가 추가될 때마다 소진된 배열 용량을 자동으로 증가시킨다.
배열 요소 추가 작업을 여러 차례 나눠서 반복적으로 진행할 경우, 각각의 추가 작업에는 일정한 시간이 소요된다.
만약 배열에 대량의 요소가 추가될 것임을 알 수 있는 경우, 추가적인 배열 용량을 미리 할당해 두는 편이 좋다.
이 경우 새로운 요소가 추가될 때마다 배열이 스스로 저장 공간을 할당하는 데 드는 시간을 줄일 수 있다.
var myArray = [Int]()
myArray.capacity
myArray.reserveCapacity(500) // 508
myArray.capacity
위 예제의 실행 결과를 보면 500개의 용량을 예약했지만 실제 할당된 공간은 그 보다 크다는 것을 알 수 있다. 이는 스위프트가 실제 성능으 고려해 실제 요청한 양 이상을 할당한 것으로 볼 수 있으며, 최소한 예약한 배열 용량만큼은 확보할 수 있음을 알 수 있다.
배열을 복사하는 경우, 저장 공간이 할당되는 동안 물리적으로 구분되는 별도의 복사물이 만들어지지 않는다. 이는 스위프트에서 제공하는 카피온라이트copy-on-write 기능으로서, 하나 이상의 배열 인스턴스가 동일한 버퍼를 공유하는 변환 작업mutating operation이 완료될 때까지는 배열 요소가 복사되지 않음으로 나타낸다.[3]
배열 초기화
구조체, 클래스, 열거형의 초기화 작업을 위해 init 메서드를 사용한다.
이와 같은 초기화 방식은 클래스 이름을 이용해서 정의하는 클래스 생성자 또는
클래스 컨스터럭터class constructor와 유사함을 알 수 있을 것이다.
오브젝티브C 에서 init 메서드는 초기화한 객체를 직접 반환하고, 호출 객체는
클래스를 초기활 때 반환 값이 nil 인지 확인한다.
이때 nil 이 반환됐다면 초기화 과정이 실패했음을 의미한다.
스위프트에서는 이와 같은 확인 기능을 실패 가능 초기화failable initialization라고 한다.
스위프트 표준 라이브러리는 세 가지 타입의 배열을 구현하기 위해 네 가지 초기화 메서드를 제공한다.
이 외에도, 배열 초기화를 위해 하나 혹은 그 이상의 요소로 구성된 컬렉션을 정의할 수 있는 딕셔너리 객체를 사용할 수 있다. 이 때 개별 요소는 쉼표 기호로 구분하여 추가한다.
- 배열 생성을 위한 정식 표현 문법
var myArray = Array<Int>() // []
- 배열 생성을 위한 단축 표현 문법
var myArray = [Int]() // []
- 배열 리터럴 선언 방식
var myArray = [1, 2, 3] // [1, 2, 3]
- 기본값으로 배열 생성하기
var myArray = Array(repeating: 2, count: 5) // [2, 2, 2, 2, 2]
배열에 요소 추가 및 업데이트
배열에 새로운 요소를 추가할 때는 append(_:) 메서드를 사용한다.
이 메서드는 배열의 맨 마지막 부분에 새로운 요소를 추가한다.
var myArray = [Int]()
myArray.append(50) // [50]
기존의 컬렉션 타입이 있을 때도 append(_:) 메서드를 사용할 수 있다.
이 메서드는 배열의 맨 마지막 부분에 새로운 요소를 추가한다.
특정한 배열 인덱스 위치에 요소를 추가하려는 경우 insert(_ newElement: at:) 메서드를 사용한다.
myArray.insert(30, at: 1) // [50, 30]
특정 인덱스 위치의 배열 요소를 교체하려 할 경우 서브스크립트 문법을 사용할 수 있다.
myArray[0] = 10 // [10, 30]
배열에서 요소 가져오기 및 삭제
배열의 특정 요소를 가져오기 위한 방법은 여러 가지가 있다. 해당 배열의 인덱스를 알고 있꺼나 인덱스의 범위를 알고 있는 경우 서브스크립트 기법을 사용할 수 있다.
var myArray = [1, 3, 5, 7, 9, 100]
- 인덱스 값으로 배열 요소 가져오기
myArray[2] // 5
- subRange로
ArraySlice요소 가져오기
myArray[2..<5] // [5, 7, 9] 인덱스 2 이상 5 미만
myArray[2...5] // [5, 7, 9, 100] 인덱스 2 이상 5 이하
- 반복문을 통해 요소 가져오기
for element in myArray {
print(element) // 1, 3, 5, 7, 9, 100
}
딕셔너리 가져오기 및 초기화하기
딕셔너리는 동일한 데이터 타입이 키와 값 쌍으로 묶여 있는 무순위 컬렉션unordered collection이며 순위를 별도로 지정할 수 있는 방법은 없다. 각각의 값은 딕셔너리 내에서 해당 값의 이름표identifier와 같은 역할을 하는 키와 연결되어 있다.
딕셔너리의 키 타입은 Hashable 프로토콜을 준수해야 한다.
딕셔너리 초기화하기
딕셔너리 역시 배열과 마찬가지로 정식 선언 문법과 단축 선언 문법이 있다.
- 딕셔너리 정식 선언 문법
var myDict = Dictionary<Int, String>()
- 딕셔너리 단축 선언 문법
var myDict = [Int:String]()
키와 값이 모두 동일한 타입의 데이터로 구성된 경우, 딕셔너리 선언에서 해당 데이터 타입을 별도로 명시할 필요는 없다. 스위프트는 초기화를 진행하면서 키/값 쌍을 통해 데이터 타입을 자동으로 추측하므로 개발자 입장에서는 불필요한 코드 입력을 줄일 수 있다.
- 명시적인 딕셔너리 선언
var myDict: [Int:String] = [1: "One", 2: "Two", 3: "Three"]
- 단축형 딕셔너리 선언
var myDict = [1: "One", 2: "Two", 3: "Three"]
키/값 쌍 추가, 변경, 삭제
새로운 키/값 쌍을 추가하거나 기존의 쌍을 업데이트하려고 할 경우, updateValue(_:forKey:) 메서드 또는
서브스크립트 문법을 사용할 수 있다. 키가 존재하지 않는 경우, 새로운 키/값 쌍이 추가되며,
기존의 쌍은 새로운 값으로 업데이트 된다.
- 딕셔너리에 새로운 쌍 추가
myDict.updateValue("Four", forKey: 4) // [2: "Two", 1: "One", 3: "Three", 4: "Four"]
- 서브스크립트 문법으로 새로운 쌍 추가
myDict[5] = "Five" // [2: "Two",5: "Five", 1: "One", 3: "Three", 4: "Four"]
서브스크립트 문법과 달리 updateValue(_:forKey:) 메서드는 교체된 값을 반환하거나 새로운 키/값 쌍이 추가된 경우 nil` 을 반환한다.
키 값 쌍을 삭제하려면 removeValue(forKey:) 메서드를 사용한다.
서브스크립트 문법에서는 키에 nil 을 전달하면 해당 대상이 삭제된다.
- 딕셔너리에서 키/값 쌍 삭제하고 삭제된 쌍 반환하기
let removed = myDict.removeValue(forKey: 1) // "One"
// [2: "Two",5: "Five", 3: "Three", 4: "Four"]
- 서브스크립트로 딕셔너리에서 키/값 쌍 삭제하기
myDict[2] = nil
// [5: "Five", 3: "Three", 4: "Four"]
서브스크립트 문법과 달리 removeValue(forKey:) 메서드는 삭제된 값을 반환하거나 키가 존재하지 않을 경우 nil` 을 반환한다.
딕셔너리에서 값 가져오기
서브스크립트 문법을 이용해서 딕셔너리에서 특정 키/값 쌍을 가져올 수 있다. 키는 서브스크립트의 대괄호 속에 넣어 전달하며, 해당 키가 딕셔너리 상에 존재하지 않을 경우, 서브스크립트 옵셔널optional을 반환한다. 이때 옵셔널 바인딩optional binding 또는 강제 언래핑forced unwrapping을 통해 해당 키/값 쌍을 가져옥나, 해당 키/값 쌍이 없다고 결론 지을 수도 있다. 해당 키가 반드시 존재한다는 확신이 없다면, 강제 언래핑을 해서는 안되며 이 경우 런타임 에러가 발생한다.
- 옵셔널 바인딩
var myDict = [1: "One", 2: "Two", 3: "Three"]
if let optResult = myDict[4] {
print(optResult)
} else {
print("Key Not Found") // "Key Not Found"
}
- 강제 언래핑
let result = myDict[3]!
print(result) // three
let errorResult = myDict[5]
print(errorResult) // nil
특정 값을 가져오는 대신, 딕셔너리를 반복적으로 순회하며 명시적으로 키/값을 분할해서 사용할 수 있는 (key, value) 튜플을 반환하도록 할 수도 있다.
let states = ["AL": "Alabama", "CA": "California", "AK": "Alaska", "AZ": "Arizona", "AR": "Arkansas"]
for (abbr, name) in states {
print("\(name) is \(abbr)")
}
// Arizona is AZ
// Arkansas is AR
// California is CA
// Alaska is AK
// Alabama is AL
딕셔너리는 무순위 컬렉션이므로, 딕셔너리의 출력 결과는 데이터의 삽입 순서와 일치하지 않을 수 있다.
딕셔너리에서 키 또는 값만을 개별적으로 가져오고 싶다면, 딕셔너리의 Keys 프로퍼티 혹은 value 프로퍼티를 사용한다.
이 프로퍼티들은 컬렉션 타입에 대응하는 LazyMapCollection 인스턴스를 반환한다.
이렇게 반환된 딕셔너리 요소는 기본 요소에 표함된 변환 클로저 함수의 호출에 의해
정보를 읽을 때마다 지연 처리되고, 키와 값은 각각 .0, .1 멤버가 되어
딕셔너리의 키/값 쌍을 동일한 순서대로 나타난다.
- for...in keys
for key in states.keys {
print("State is \(key)")
}
// State is AL
// State is AR
// State is CA
// State is AZ
// State is AK
- for...in values
for value in states.values {
print("State is \(value)")
}
// State is California
// State is Alabama
// State is Arizona
// State is Alaska
// State is Arkansas
딕셔너리는 기본적으로 무순위 컬렉션이지만, 가끔은 딕셔너리를 순회하면서
순위 목록으로 정돈해야 할 경우도 있다. 이 경우 전역 메서드인 sorted(by:) 를 이용하자.
이 메서드는 딕셔너리 요소를 배열 요소처럼 정렬한 후 해당 배열을 반환한다.
let sorted = states.sorted(by: {$0.0 < $1.0}) // 키 값을 기준으로 정렬
for value in sorted {
print("State is \(value)")
}
// State is (key: "AK", value: "Alaska")
// State is (key: "AL", value: "Alabama")
// State is (key: "AR", value: "Arkansas")
// State is (key: "AZ", value: "Arizona")
// State is (key: "CA", value: "California")
세트 선언
세트set는 서로 중복되지 않고 unique, nil 이 포함되지 않은 non-nil 순위를 정의할 수 없는
무순위 컬렉션이다. 세트는 Hashable 프로토콜를 준수해야 하며, 스위프트의 모든 기본 타입은 기본적으로
Hashable 프로토콜을 따르도록 설계되었다. 연관 값을 사용하지 않는 열겨헝의 case 값 역시 기본적으로
Hashable 프로토콜을 준수한다. 세트에 커스텀 타입을 저장 시 해당 타입 역시 반드시 Hashable 프로토콜과
Equtable 프로토콜을 준수해야 한다.
순위가 중요치 않은 배열은 세트로 저장해도 큰 차이가 없으며, 이 경우 해당 요소가 서로 중복되지 않도록 주의하기만 하면 된다. 세트는 배열에 비해 매우 효율적이며, 데이터 접근 속도 역시 세트가 훨씬 빠르다. 예를 들어, 배열의 크기가 n 일 때 배열 요소에 대한 최악의 검색 시나리오의 효율을 O(n) 이라 한다면 세트의 효율은 크기에 관계 없이 O(1) 수준을 유지한다.
세트 초기화
세트는 다른 컬렉션 타입과 달리 포함된 타입을 스위프트가 추측하지 않으므로 직접 Set 타입을 명시적으로
선언해야만 한다.
- 세트 선언을 위한 정식 문법
var stringSet = Set<String>()
세트 초기화 시 세트 자체의 타입을 명시하지 않아도 된다. 단, 세트에 속한 배열 요소가 같은 타입이어야 한다.
- 배열 요소로 세트 초기화
var stringSet: Set = ["Kim", "Park", "Son"]
세트 요소 변경 및 가져오기
세트는 세트에 포함된 엘리먼트를 조작하기 위한 여러 메서드를 제공한다. 주요 메서드는 다음과 같다.
insert(_:): 세트에 새로운 요소 추가contains(_:): 특정 요소가 세트에 포함되어 있는지 여부 확인remove(_:): 삭제하려는 인스턴스를 아는 경우 요소 삭제, 삭제하려는 요소가 없는 경우nil반환remove(at:): 삭제하려는 인스턴스의 인덱스를 아는 경우 요소 삭제removeFirst(): 세트의 수가 0보다 큰 경우 첫 요소 삭제removeAll(): 세트 내 모든 요소 삭제removeAll(keepingCapacity:): 세트 내 모든 요소 삭제 및 keepingCapacity가 참인 경우 세트 용량 감소 x
var mySet: Set = ["Hello", "iOS", "Swift", "World"]
mySet.insert("Kim") // (inserted: true, memberAfterInsert: "Kim")
if mySet.contains("Park") {
print("Hello Park")
} else {
print("Not Found Park") // Not Found Park
}
let a = mySet.remove("Park") // nil
if let idx = mySet.index(of: "iOS") {
mySet.remove(at: idx) // "iOS"
}
mySet.forEach { print($0) }
// Hello
// World
// Swift
// Park
mySet.count // 4
mySet.capacity // 6
mySet.removeAll(keepingCapacity: true)
mySet.count // 0
mySet.capacity // 6
mySet = ["Hello", "iOS", "Swift", "World"]
mySet.count // 4
mySet.capacity // 6
mySet.removeAll()
mySet.count // 0
mySet.capacity // 0
세트 역시 배열이나 딕셔너리와 마찬가지로 for...in 과 같은 순환문을 이용해 세트 내요소를 순회할 수 있다.
이 경우 세트는 무순위 이므로 순회 순서가 매번 달라지지만, 딕셔너리와 마찬가지로 sort 메서드를 사용해
정렬할 수 있다.
세트 연선자
세트는 수학에서의 집합 개념을 기반으로 만든 타입으로, 수학의 집합 연산과 같은 두 개 세트의 비교를 위한 다양한 메서드를 제공한다.
세트의 비교 연산
세트 타입은 두 세트 간의 연산을 위한 합집합, 교집합 연산을 포함, 네 개의 연산 메서드를 제공한다. 그 결과
새로운 세트가 반환 되거나 InPlace 와 같은 대체 메서드를 이용해 기존 세트의 내용을 대체하기도 한다.
-
union(_:): 새로운 합집합 세트를 만들고 반환 -
formUnion(_:): 새로운 세트를 만들고, 두 개 세트의 합집합으로 원본 세트를 업데이트 -
intersection(_:): 새로운 교집합 세트를 만들고 반환 -
formIntersection(_:): 새로운 세트를 만들고, 두 개 세트의 교집합으로 원본 세트를 업데이트 -
symmetricDifference(_:): 새로운 여집합 세트를 만들고 반환 -
formsymmetricDifference(_:): 새로운 세트를 만들고, 두 개 세트의 여집합으로 원본 세트를 업데이트 -
subtracting(_:): 새로운 차집합 세트를 만들고 반환 -
subtract(_:): 새로운 세트를 만들고, 두 개 세트의 차집합으로 원본 세트를 업데이트
부분 집합 및 동등 연산자
두 개의 세트에 속한 내뷰 요소가 서로 완전히 같은 경우, 두 세트는 동등하다고 표현한다. 세트는 무순위
컬렉션이므로, 요소의 순서는 동등 여부와 관계 없다. 두 세트 간의 비교는 동등 연산자인 == 를 사용한다.
또한 다음과 같은 메서드를 활용할 수 있다.
isSubset(of:): 어떤 세트의 요소가 특정 세트에 모두 포함되어 있는지 확인isStrictSubset(of:): 어떤 세트의 요소가 특정 세트에 모두 포함되어 있지만, 동등 집합은 아님을 확인isSuperset(of:): 특정 세트의 모든 요소가 또 다른 세트에 모두 포함되어 있는지 확인isStrictSuperset(of:): 특정 세트에 모든 요소가 또 다른 세트에 모두 포함되어 있지만, 동등 집합은 아님을 확인isDisjoint(with:): 두 세트에 공통 요소가 포함되어 있는지 여부 확인
튜플의 특징
튜플tuples은 오브젝티브C에는 없는 고급 타입이다. 튜플은 배열, 딕셔너리, 세트와 같은 컬렉션
타입은 아니지만, 컬렉션 타입과 매우 비슷한 특징을 지닌다. 튜플에는 하나 이상의 데이터 타입을 함께 담을 수
있으며, 배열 등 다른 컬렉션 타입과 달리, 내부 요소들이 모두 같은 타입일 필요는 없다. 튜플은 컬렉션 타입이
아니기 때문에, SequenceType 프로토콜을 준수할 피료가 없으며, 내부 요소의 순회는 불가능하다.
튜플은 한 덩어리의 데이터를 저장하거나 전달하기 위한 목적으로 사용된다. 튜플은 별도의 구조체 타입을 사용하지 않고도 하나의 값으로 여러 타입의 데이터를 반환해야 하는 경우 특히 유용하다. 그러나 튜플의 반환 결과가 임시 범위를 넘어설 경우 구조체와 클래스와 같은 특정 타입을 만드는 것이 낫다.
무기명 튜플
튜플은 어떤 숫자 또는 어떤 데이터 타입을 조합해서 만들 수 있다. 이 때 타입에 대한 정보는 컴파일러가 추측을 통해 판단하여 결정한다. 만일 리터럴 타입에 대한 판단을 컴파일러에게 맡기는 것을 원치 않을 경우 직접 타입을 명시할 수 있다.
let responseCode = (401, "Invalid file contents", 123456789) // 타입 추론
let responseCode2: (Int, String, Int) = (401, "Invalid file contents", 123456789) // 타입 명시
튜플에 개별 요소에 접근하는 방법은 인덱스 값을 쓰거나 개별 요소를 상수 또는 변수로 분할하는 방법이 있다.
print(responseCode.0) // 401
let (code, message, offset) = responseCode
print(code) // 401
기명 튜플
튜플의 개별 요소에 이름을 붙일 수 도 있다. 기명 튜플은 코드를 더 쉽게 이해할 수 있게 해주며, 메서드를 통해 튜플을 반환할 때 특정 인덱스 위치에 어떤 값이 있는지 알기 쉽게 도와준다.
let responseCode = (code: 401, message: "Invalid file contents", offset: 123456789)
print(responseCode.code) // 401
[1]- Choosing Between Structures and Classes - Apple Document - Choosing Between Structures and Classes - 번역
[2]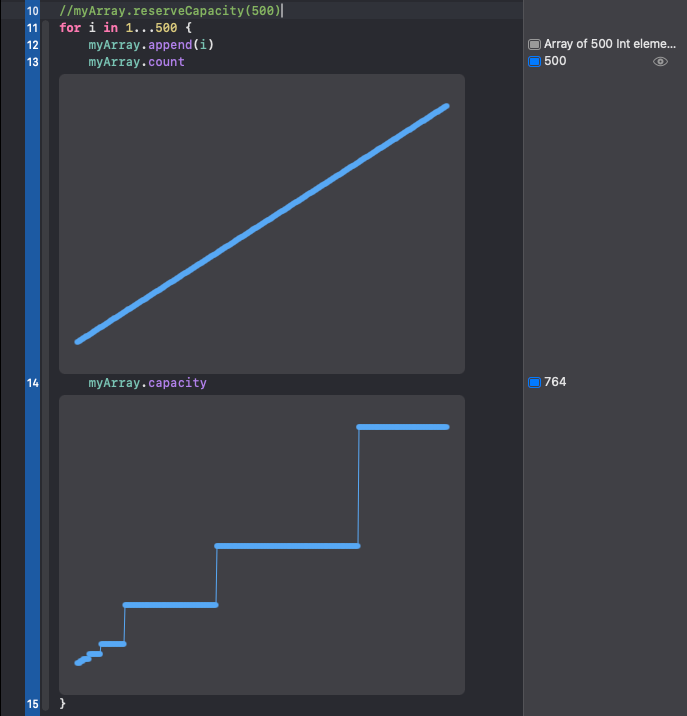
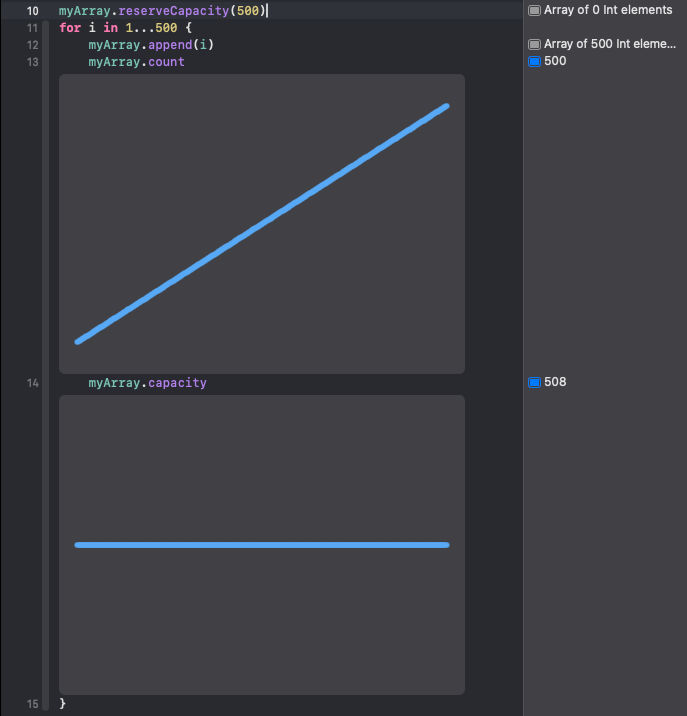
위 이미지를 확인해보면, 기하급수적 증가 전략을 활용해 저장 공간을 할당하는 것을 확인해볼 수 있다.
[3]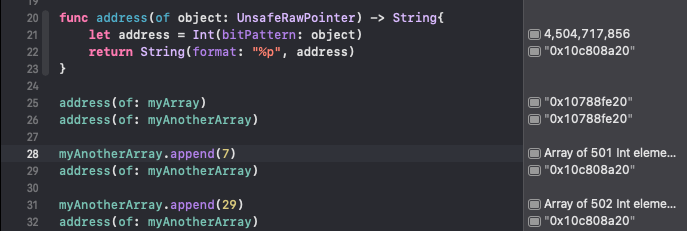
복사 시 메모리 값은 동일하지만 값이 변경 된 이후에 메모리 값이 변경되었음을 확인할 수 있다.